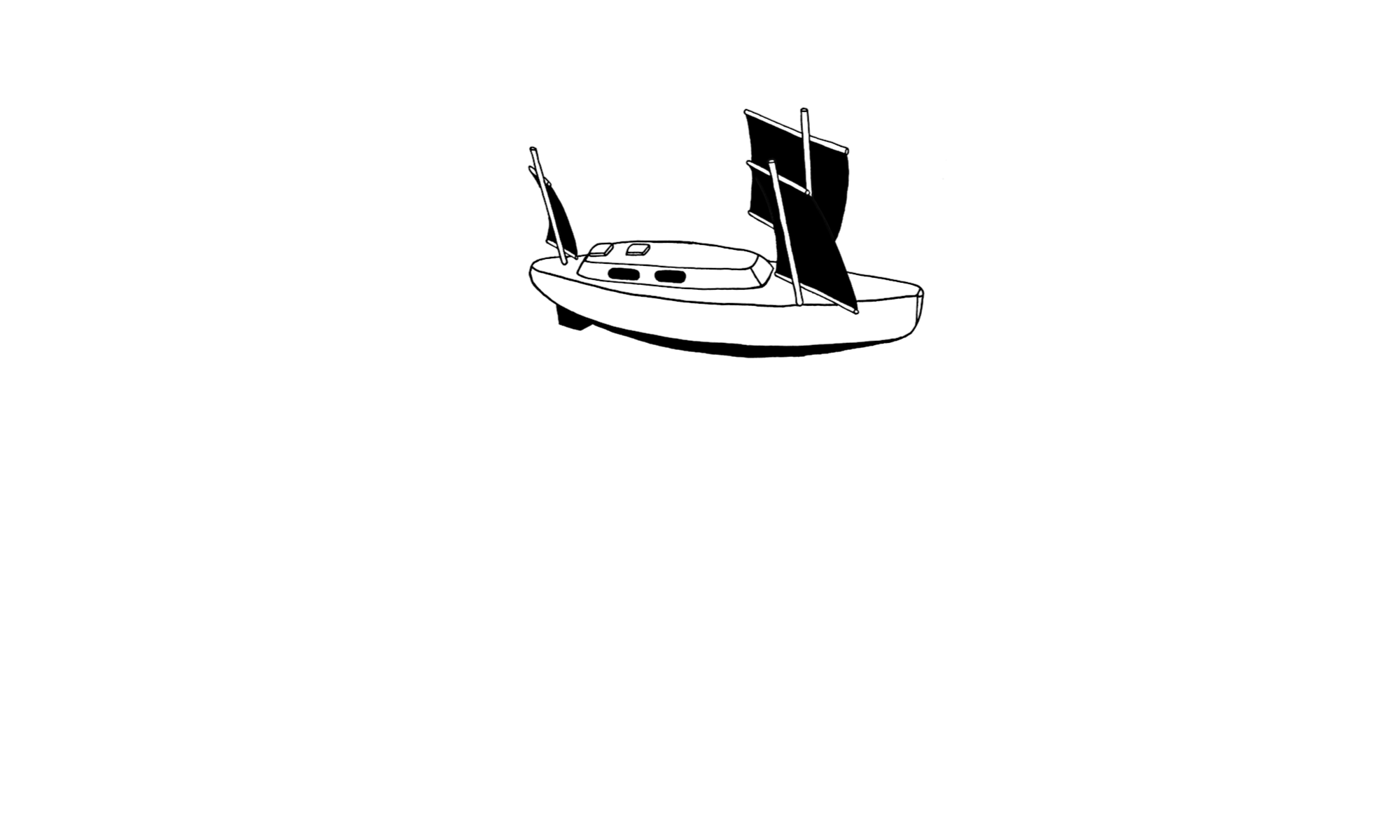
THE SAILS OF YRVIND TEN
The sails of YRVIND TEN has four corners. There is a 2.5 meter boom at the bottom and a 2.3 meter yard at the top – they are parallel. The halyard is placed 40 % from the leading edge on the yard. The booms downhaul is placed 20 % from the leading edge. The sail is not attached to the mast except by the halyard. Most people will classify it as a balanced lug but it isn’t necessarily so. For example a different downhaul fastened at the stem can be placed further aft along the boom when sailing downwind. In that configuration the sail becomes a square sail and creates a lifting force. Good to have in windy weather.
A square sail has the highest lifting force of all planforms when running free. Besides that there are some other interesting aspects of a square sail running down wind.

Ever wondered why the shaft or rachis of a flying feather is not in the middle? Well foils have their center of lift located a third from the leading edge. The shaft is located were the biggest forces are.
Ever been curios of the way a leaf falls, why it moves from side to side keeping the same side down? The reason is as soon air starts flow over its surfaces a center of effort is created about 30% from the leading edge. That side starts moving up against gravity. That causes that reduces the speed of the flow. After it stops it falls the other way because it is now slanted that way. A new leading edge is created and the process is repeated. The result is that it falls down in a zigzag fashion.
The same happens to a square sail running downwind. As long as the wind is from exactly behind the pressure is in the middle of the sail. As soon as the wind start to come in from one side the center of effort moves to that side bringing the boat back on its course, making the boat self-steer downwind. A boat has more inertia than a leaf therefore the zigzag movement is in slow motion. Matt Layden uses that effect to self-steer his Paradox downwind. First time he entered the Water Tribe Everglades Challenge he did win by more than a day.
Sailing in deep water I always use a preventer. A preventer is a line that leads forward from the end of the boom. That way the boom cannot accidently swing back and cause trouble. In this configuration the boom is already at the steam and forward of my steam there is nothing. But by fastening the preventer on the opposite side of the downhaul it locks the boom. The sheet and the preventer pulls back. Between them the downhaul pulls forward thus locking the sail.
YRVIND TEN has two masts side by side. The masts are connected with a bar that has both of its ends fixed to the masts. That creates a system that can take up torsion and bending. The two masts thus support each other in all directions. Any force on one mast is being taken up by the whole system. One mast can therefore take up nearly twice the load compared to if it had not been connected to its Siamese twin. The structure also makes a good climbing frame.
Out there no one will take me to court if I use two halyards on the same sail. By moving the halyards point of attachment on the yard I can convert the sail from lugsail to square sail and in strong winds running down wind that configuration makes sense.
Each sail is 6 square meter or about 65 square feet. It is only in light wind I will use the two sails or 12 square meters. I do not drive my boats at maximum speed nor do I drive my car at maximum speed one soon tires of it and sailing or driving at full speed creates a lot of disadvantages like danger and break downs and discomfort and fatigue. Speed is for novices. After the initial thrill focusing on the same speed gets boring even if it is fast.
The relation between speed and power is not always appreciated. Here is an example from one of Phillips Birt books: A 3-ton powerboat of 25 feet waterline length needs
3 hp to reach 5 knots
6.5 hp to reach 6 knots
15 hp to reach 7 knots and
26 hp to reach 8 knots.
That is to increase speed by 60% power needs to be increased by 867%.
I do not sail to reach the other shore as fast as possible. I sail to have deep water under my keel. In other words I like to be at sea.
1974 I sailed BRIS from St Helena to Martinique about 3800 miles in 48 days averaging 80 miles a day crossing the doldrums without engine. I had a small double ender of about 20 feet waterline length and a displacement of about 1400 kilos. The interesting thing I used only 4 square meter sail and was perfectly happy.
2011 I sailed 15 feet YRVIND.COM boat from Madeira to Martinique taking 45 days I used about 2 square meters of sail making about 2 knots I was still perfectly happy.
I do not plan to sail fast the coming trip either. Although much of it will be outside the trade wind regions I hope that I will encounter a fair amount of downwind sailing. I think one of my 6 square meter sails attached to the side by side masts as a square sail with two halyards will do fine.
For strong down windsailing I will have a four corner sail lashed to the masts at the spreader. It is nice not to have spars flying in strong winds.
Below are some sail configurations. Click once ore twice to enlarge: First Beam reach to close hauled in light wind:

The same points of sailing in stronger winds

Downwind in light air.

In stronger wind the lugsail is converted to a squaresail by moving by using two halyards and two downhauls. the downhauls is attached to the stem making the sail lifting.

In stronger winds there is reef points. Now I lashe the sails to the spreader thus reducing the compression on the mast.

In really strong winds I use a square sail set flying thus awoiding spars up in the air.

To be continued…
Regards Yrvind.